Python 爬虫是什么?
我们在网络上收集资料的过程其实就称之为爬虫(web scraping)。复制粘贴歌词、摘抄文本或数据都可以算作爬虫的一部分,但网络编程背景下的爬虫,更强调自动化,通过 Python 编程实现自动爬取资源,从而减少人力资源与精力消耗,提高效率。
注:在动手爬虫之前,程序员们还是需要考虑一些法律相关的问题。一般而言,开源或教育相关用途的爬虫并不会触及法律问题,但若用作其他商业用途或涉及一些敏感事物,爬虫也可能涉及违反服务条款甚至其他法律纠纷。同样地,有些网站也会避免爬虫而通过其他手段提高安全门槛。
在法律允许的范围内,学习使用 Python 实现自动化爬虫能让大家在资讯纷杂的网络世界中,快速地收集自己所需的资料。这篇文章将通过虚构的求职网站 Fake Python 以及使用 Lightly 展示完整的项目代码,引导大家在无需安装第三方软件的情况下,动手在浏览器中编写代码,了解 Python 爬虫。
Lightly 爬虫项目代码:https://538cd3972a-share.lightly.teamcode.com
了解网站的基础结构
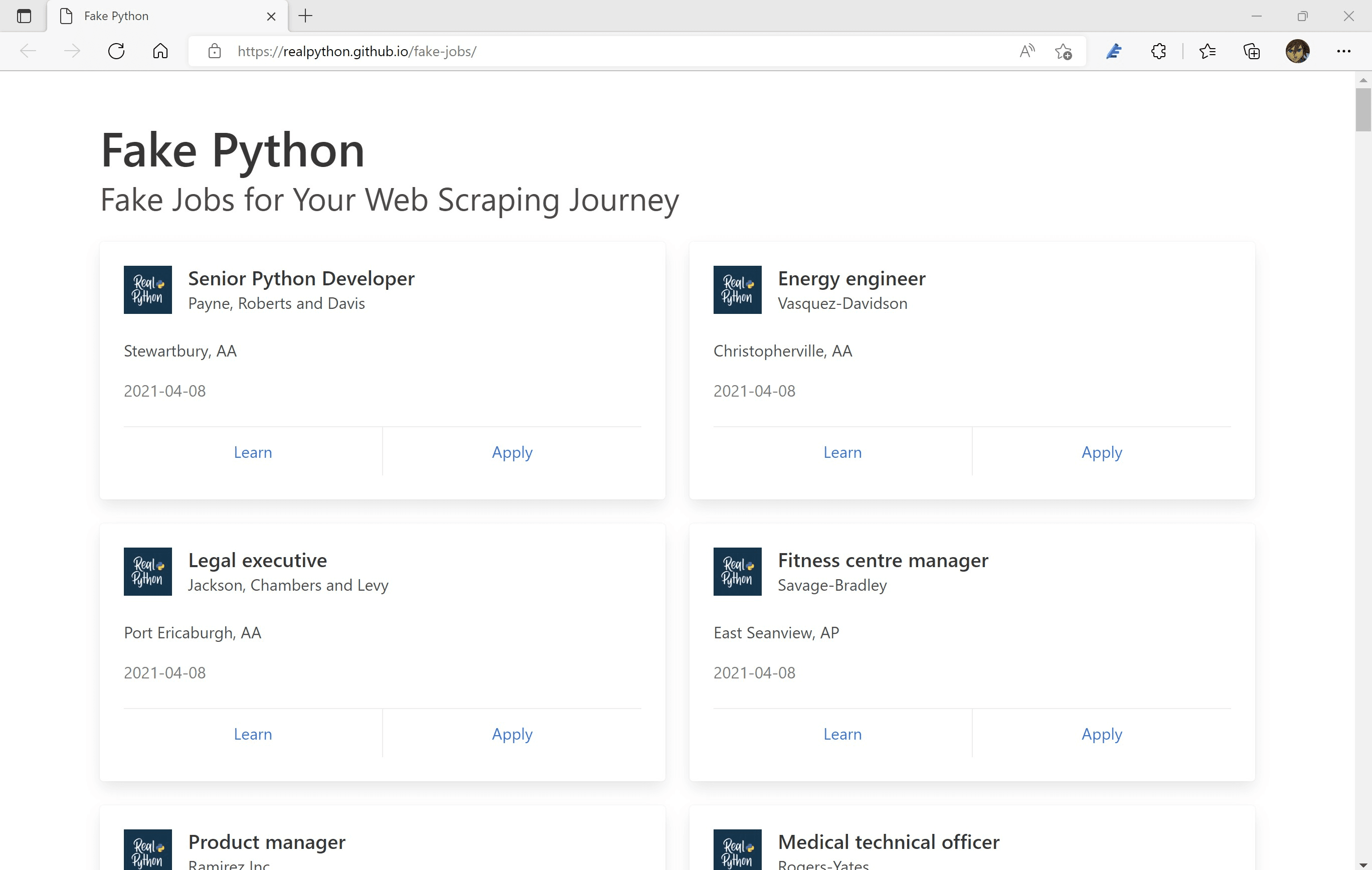
在开始编写 Python 代码前,合格的程序员还是需要具备基础的网页知识。在这里打开教程中所使用的网页:https://realpython.github.io/fake-jobs/
右键点击“查看页面源代码”,打开后将展示网页的 HTML 代码。
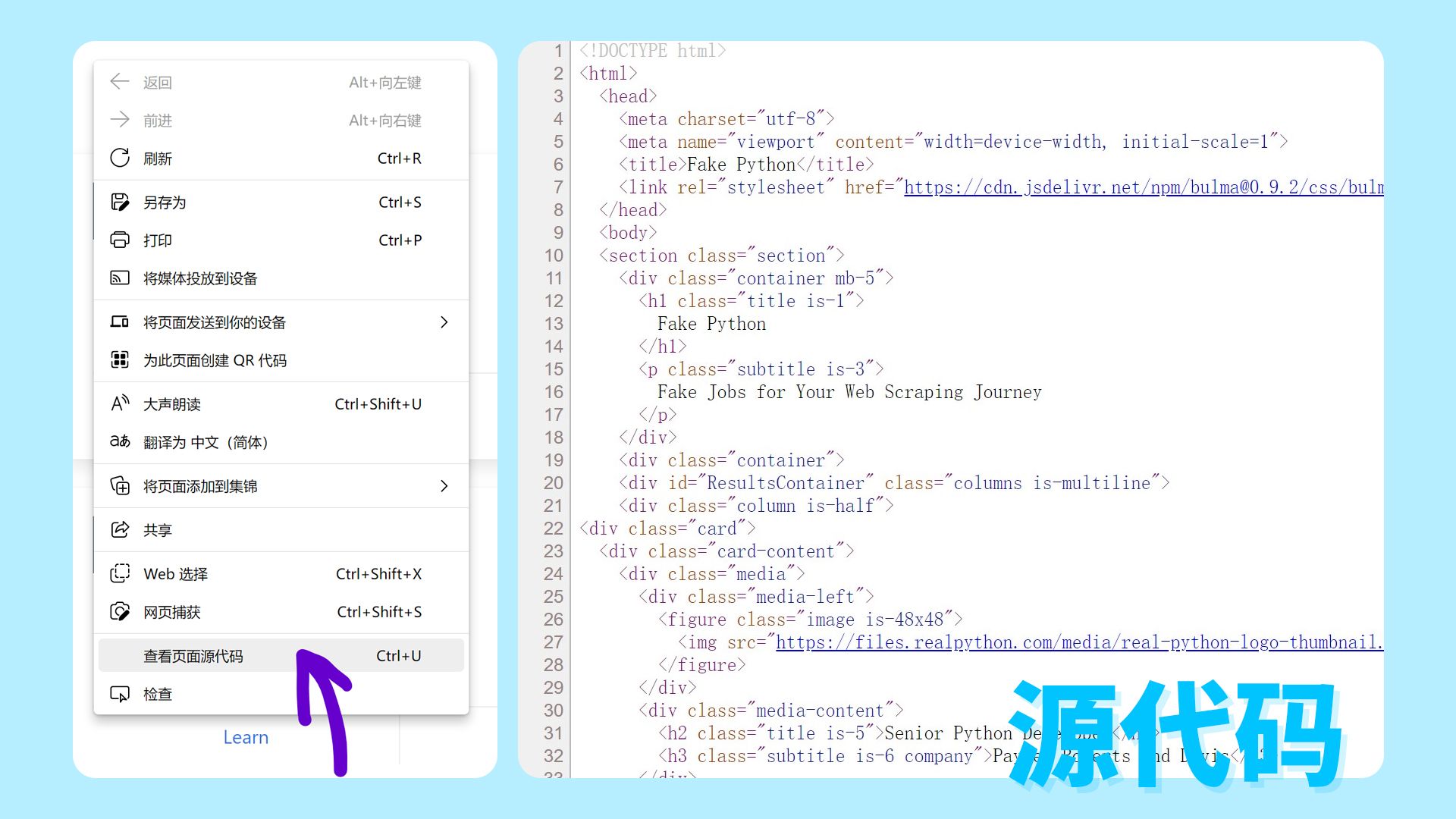
除了右键查看外,使用 Windows 的同学也可以通过 Ctrl + Shift + I (MacOS: Cmd + Alt + I)的方式调动开发人员工具,在“元素”中查看源代码。使用开发人员工具可以折叠或展开代码,也可以根据鼠标悬浮展示代码在网页中所对应的内容。
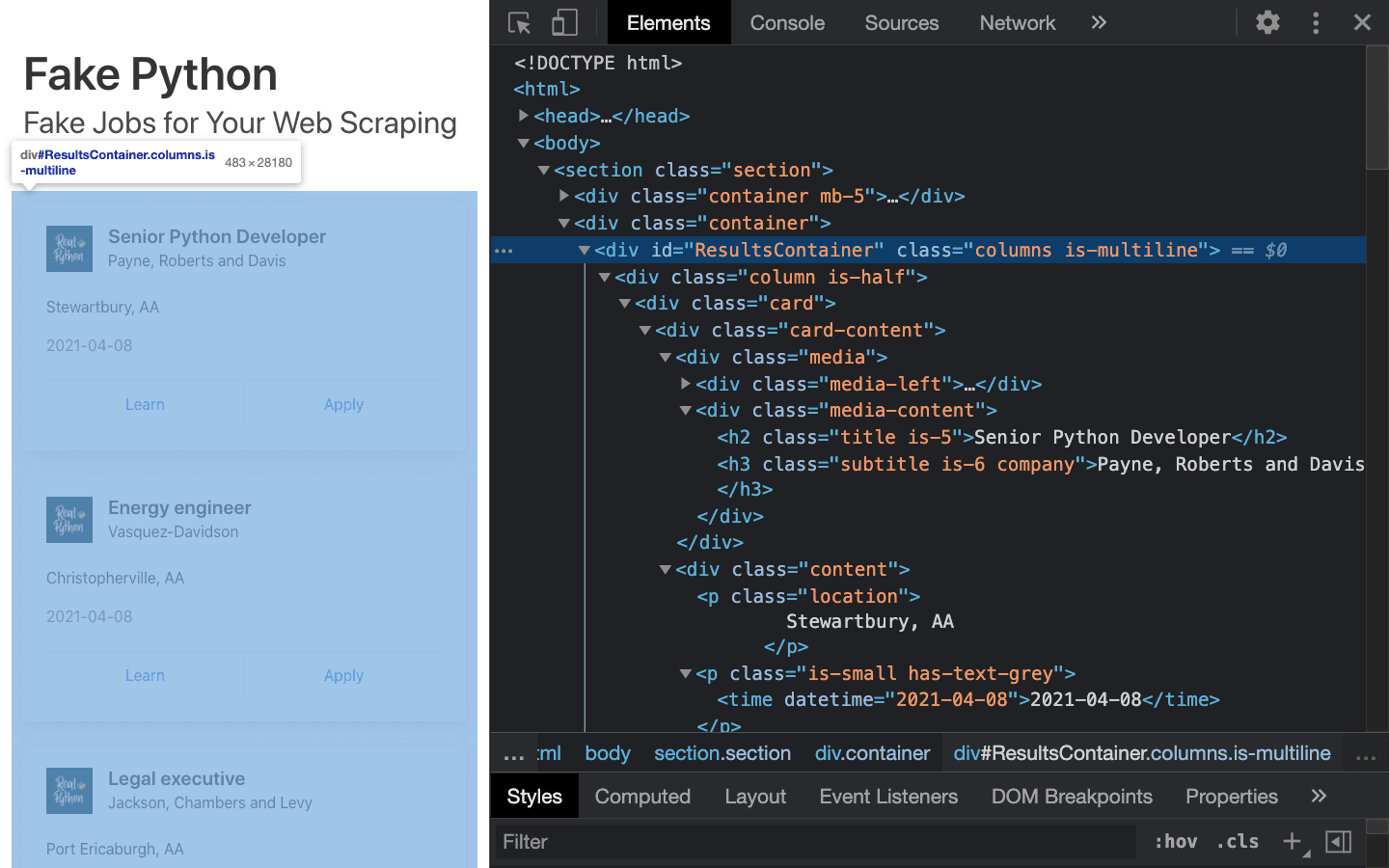
在 Python 爬虫中,同学们无需被纷乱的 HTML 代码劝退。一般而言,我们可以关注 id / class 等元素,从中找到对应的分组,即可借用 Python 和 Lightly Python在线编译器,从这些代码中分析出我们所需的内容。
先行准备:安装 requests 及 BeautifulSoup 库
初次使用 Lightly 或此前未安装 requests 及 bs4 库的同学,在开始编写项目代码前需在终端通过 pip install requests 以及 pip install bs4 分别安装依赖。
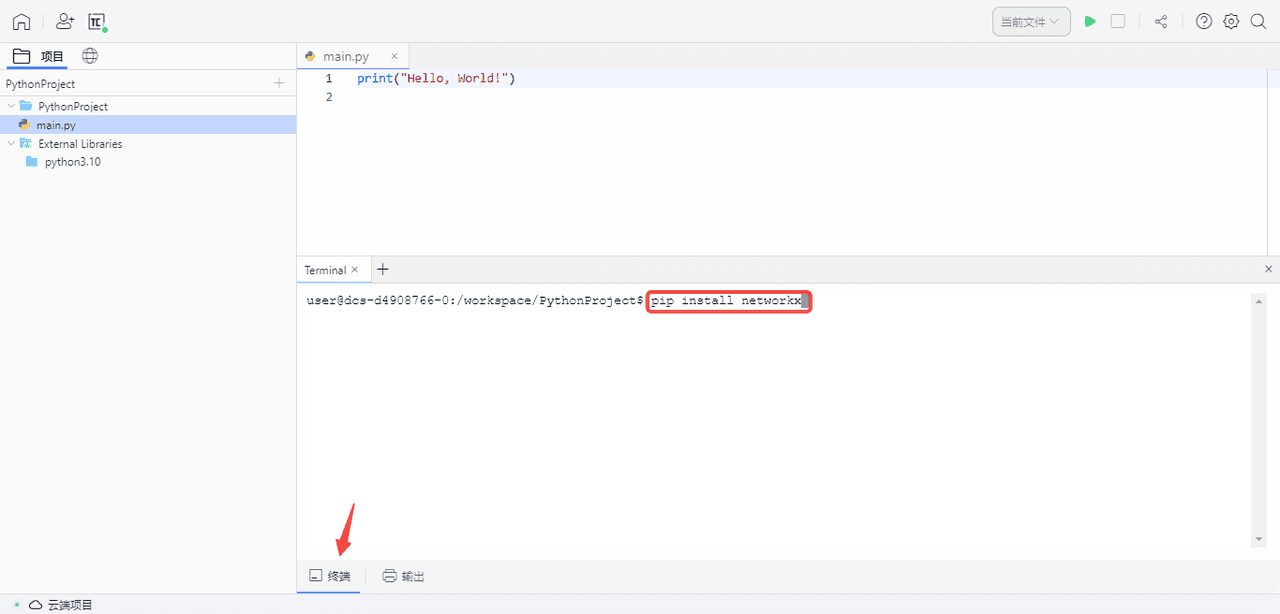
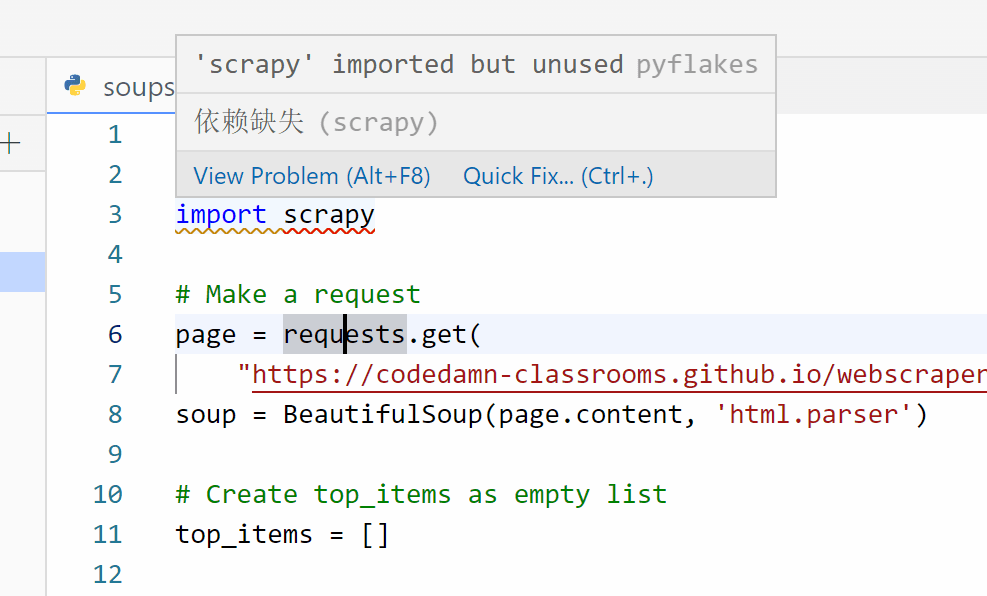
若此前忘了安装,使用 Lightly 的同学也可以通过 QuickFix 的方式,一键安装缺失依赖。
手把手实操 Python 爬虫
通过 Lightly 快照中的 Python 项目代码,复制到个人项目中进行学习:https://538cd3972a-share.lightly.teamcode.com
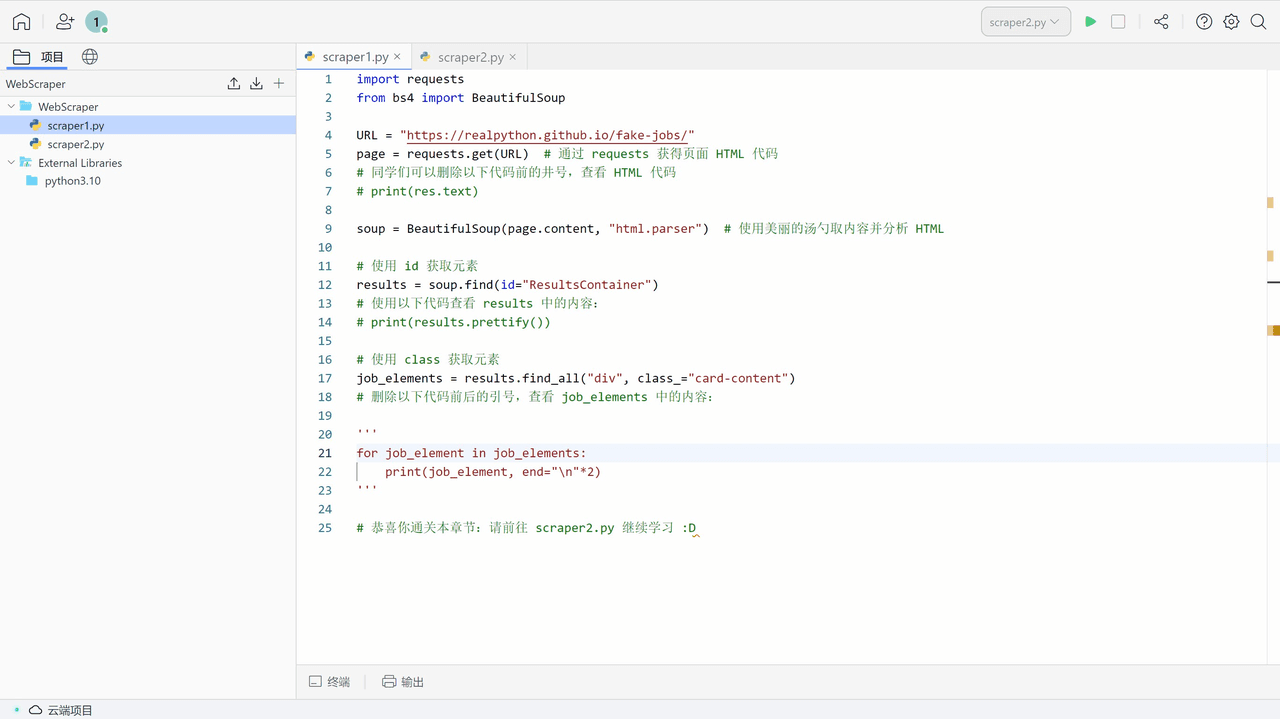
注:快照复制到个人项目后,任何修改都不会影响到原本的快照链接,同学们可放心对自己的代码进行修改,也可以随时通过快照链接再次查看源代码。
Lightly Python 爬虫实操项目代码中,分成多个章节通过代码中的注释讲解 BeautifulSoup 中的各个元素。
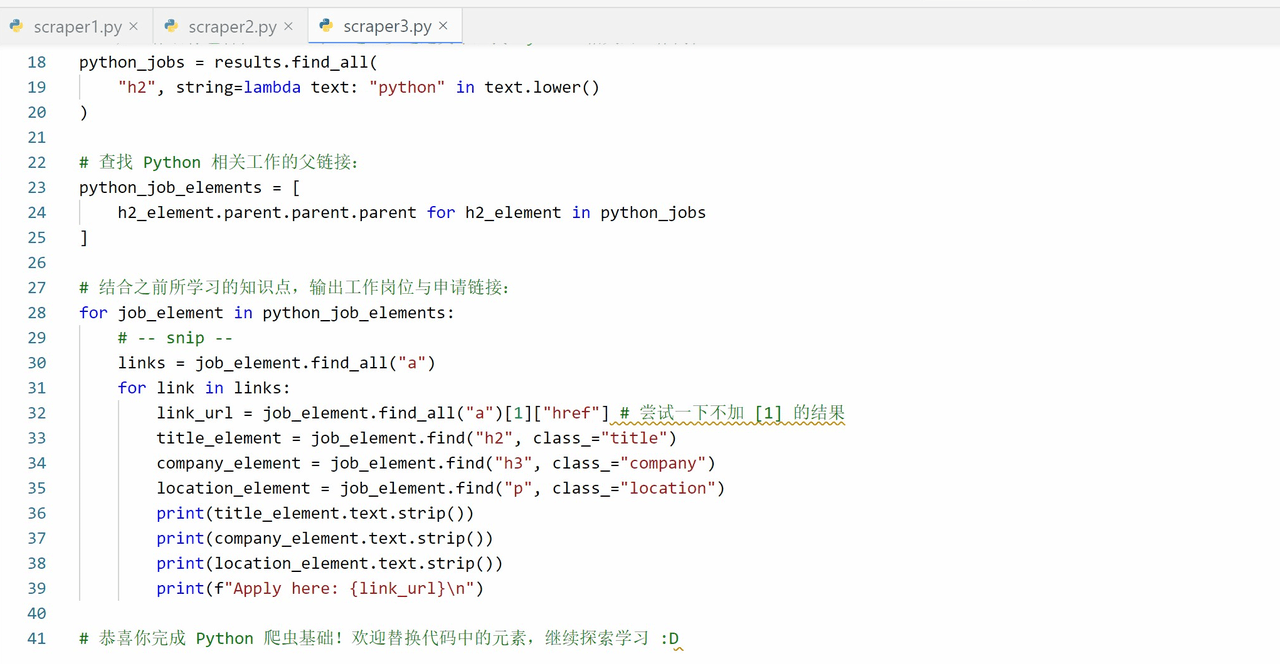
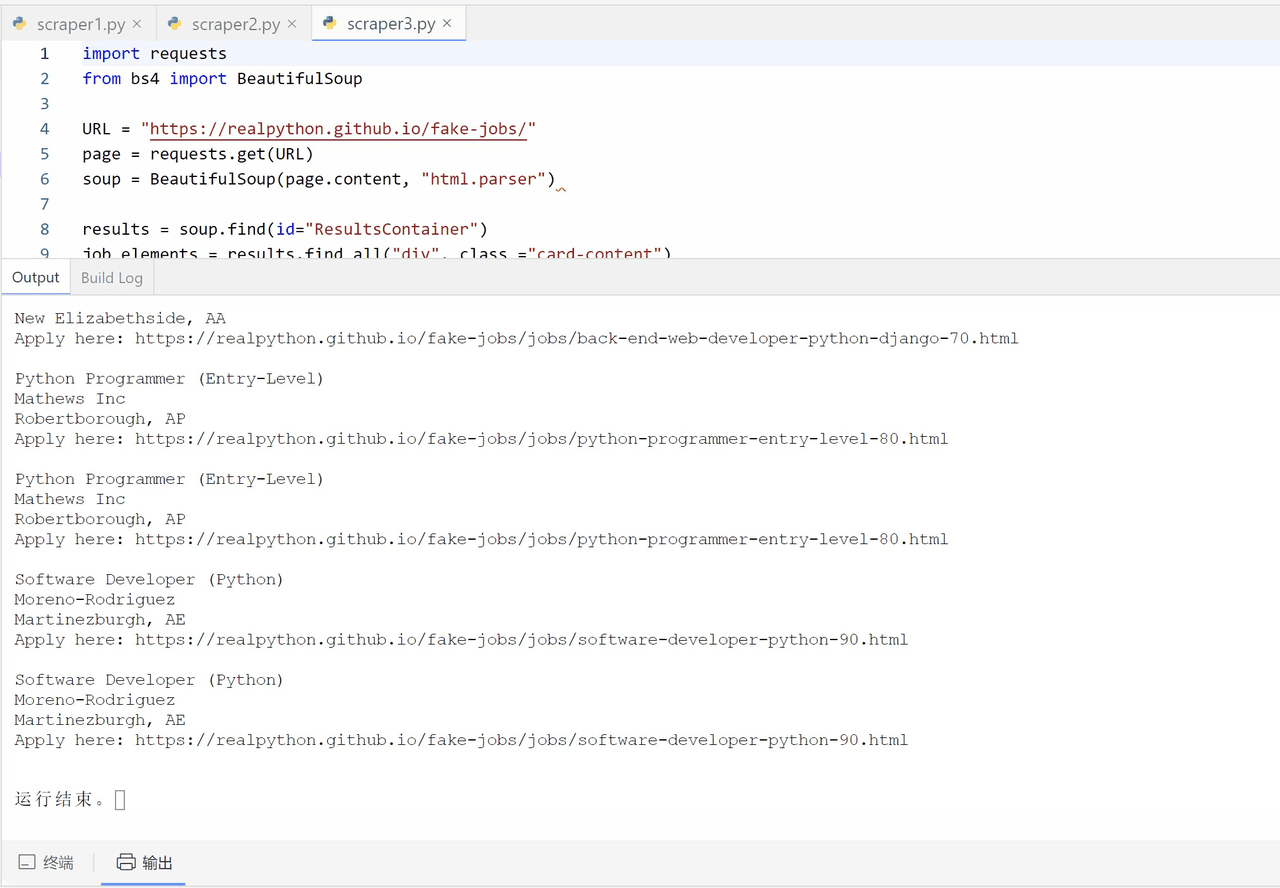
完成学习后的输出效果如下:
爬虫的挑战
此次爬虫中所使用的练习网站较为简单,但也展示了基础 Python 爬虫中需要具备的知识与应用。现实使用的网页或许会比练习中的网页更为复杂,不同编程人员所使用的编程语言、风格、安全系数等都有可能影响爬虫的难易度。
此外,对于信息更新较为频繁的网站而言,大家在学习爬虫的过程中也有可能发现每次运行的内容都可能出现变化。若网站的改动较大,过去所建立好的爬虫代码就有可能失效。因此,学习 Python 爬虫是一个常练常新的过程。在法律法规允许的范围内,进一步通过已习得的技巧多加练习与交流,才能真正地将爬虫作为有利于自己的工具,增进工作效率与个人能力。