数据分析是 Python 编程广泛应用的领域之一,数据分析员借助 Python 语法简单明晰、应用范围广泛的特性,通过爬虫、整合数据等多样化的依赖与函数,进一步提高数据分析的能力与效率。

在这篇教程中,同学将整合之前所学习的 Python 爬虫技巧,进一步学习如何将所爬取的数据储存到 CSV 文件中。 往期Python爬虫课程回顾:学习 Python 爬虫,手把手通过 Python 入门爬取网页信息
什么是 CSV 文件?
CSV 即逗号分隔值(Comma Separated Values)的缩写,是一种常用于储存表格数据的文件格式。这种文件格式在机器学习中十分常见,同时也能通过 Excel 等常见的表格处理软件打开。在 Python 编程中,程序员只需借助 csv 和 pandas 依赖即可将数据储存为 CSV 格式,供数据分析使用。
 此次的教程将使用 Lightly Python在线编译器进行实操讲解,同学们只需将项目复制到个人账户中,即可打开项目中 WebAnalyser.py 文件,使用浏览器在线编码:https://538cd3972a-share.lightly.teamcode.com
此次的教程将使用 Lightly Python在线编译器进行实操讲解,同学们只需将项目复制到个人账户中,即可打开项目中 WebAnalyser.py 文件,使用浏览器在线编码:https://538cd3972a-share.lightly.teamcode.com
安装依赖
此次教程所需的依赖包括:requests、bs4、csv 和 pandas。通过 Lightly 学习的小伙伴可直接在项目页面中,通过 import 导入依赖,再将鼠标悬浮至相应的依赖名称,一键安装缺失依赖。
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd使用 BeautifulSoup 查找所需的资料
安装好依赖后,我们可以通过 requests 和 beautifulsoup 获取 HTML 代码,并从代码中查找所需的内容。
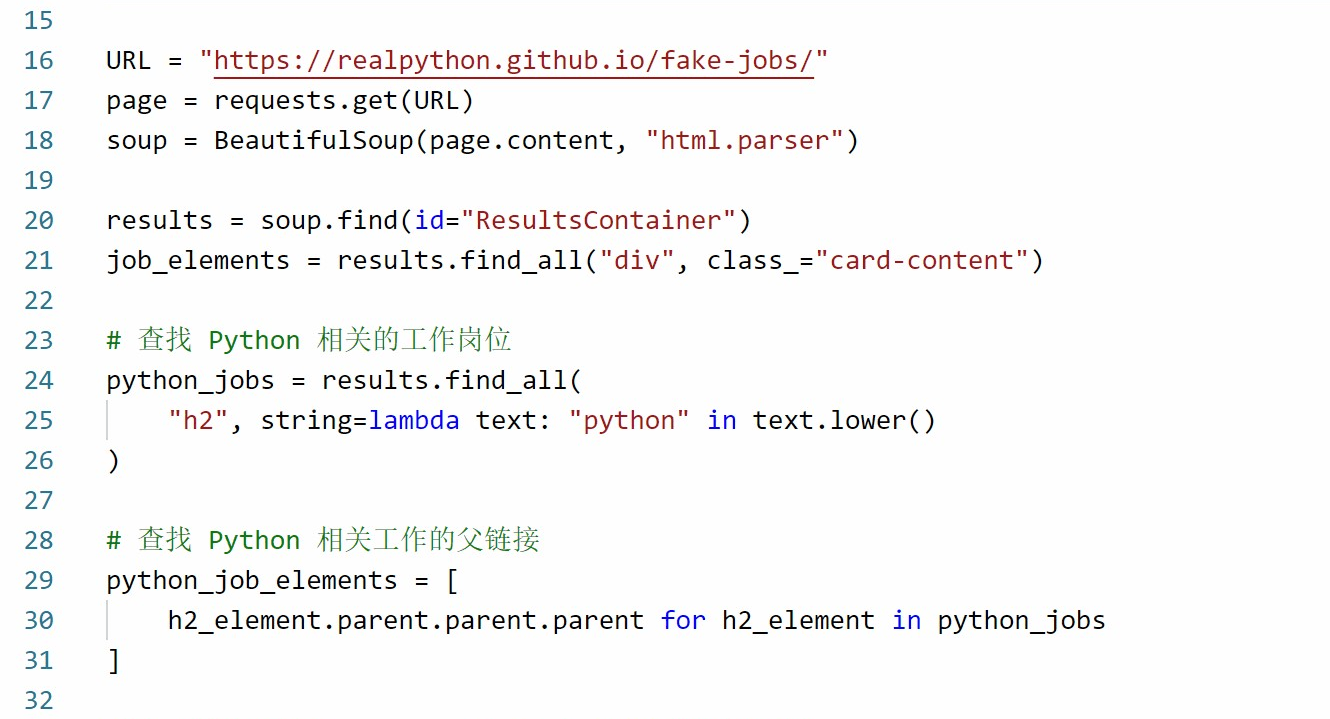
开启 CSV 文件
开启 CSV 文件的 CSV 与 pandas 代码分别如下:
# 建立 csv 文件
csvfile = open('pythonjobs.csv', 'w+')
# 使用 pandas 定义数据框架
df = pd.DataFrame(columns=['Title', 'Company', 'Location', 'Link'])‘csvfile’ ‘df’ 等变量名称可随意替换,pythonjobs.csv 等文件名称、columns 变量内的表格标题也可随表格内容适当替换。
写入 CSV 文件
开启 CSV 文件的先行工作完成后,即可通过以下代码,准备将数据内容写入文件中:
# 启用 csv 写入程序
writer = csv.writer(csvfile)
writer = csv.writer(csvfile)然后结合 Python 爬虫教程所学习的知识,进一步完善所写入的内容:

关闭 CSV 文件
确认所有内容写入后,即可再次通过代码关闭 CSV 文件,整个爬虫 + 导出 CSV 的 Python 程序便完成了:
df.to_csv('pythonjobs.csv') # 输出为 csv 文件
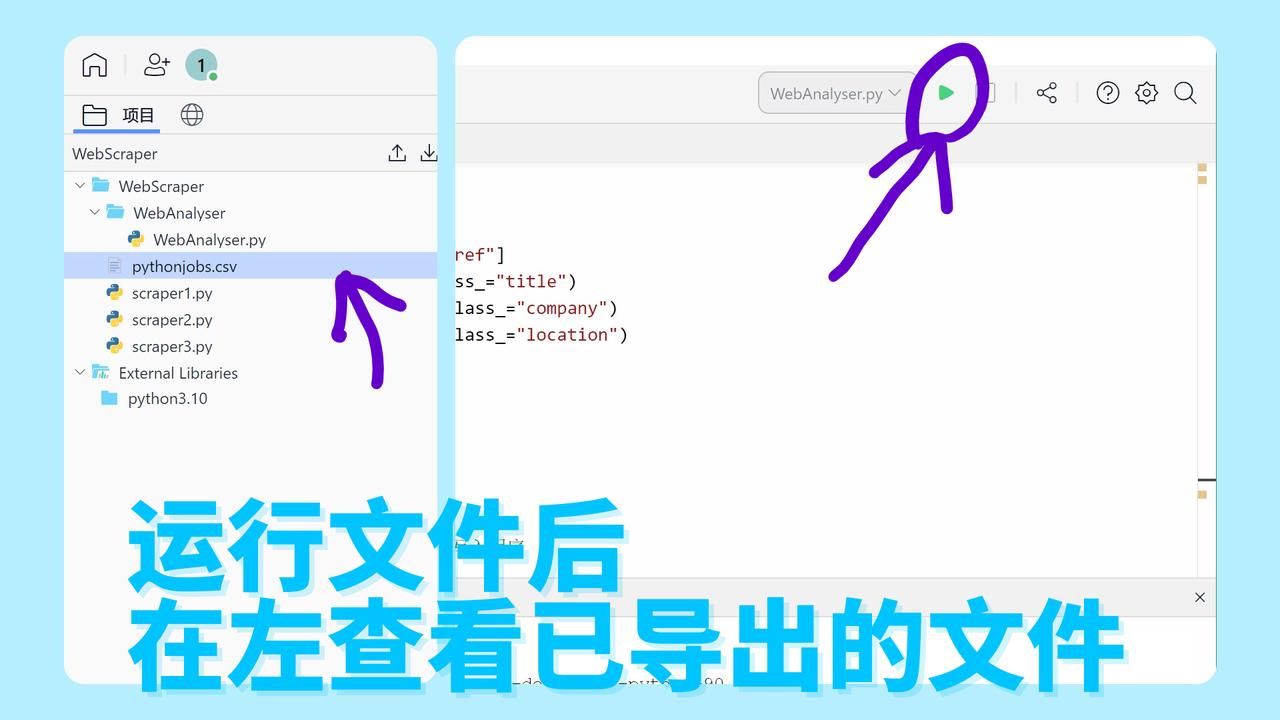
csvfile.close() # 关闭 csv 文件在 Lightly IDE 右上角点击运行程序后,即可在左侧的项目栏中找到已生成的 pythonjobs.csv 文件:
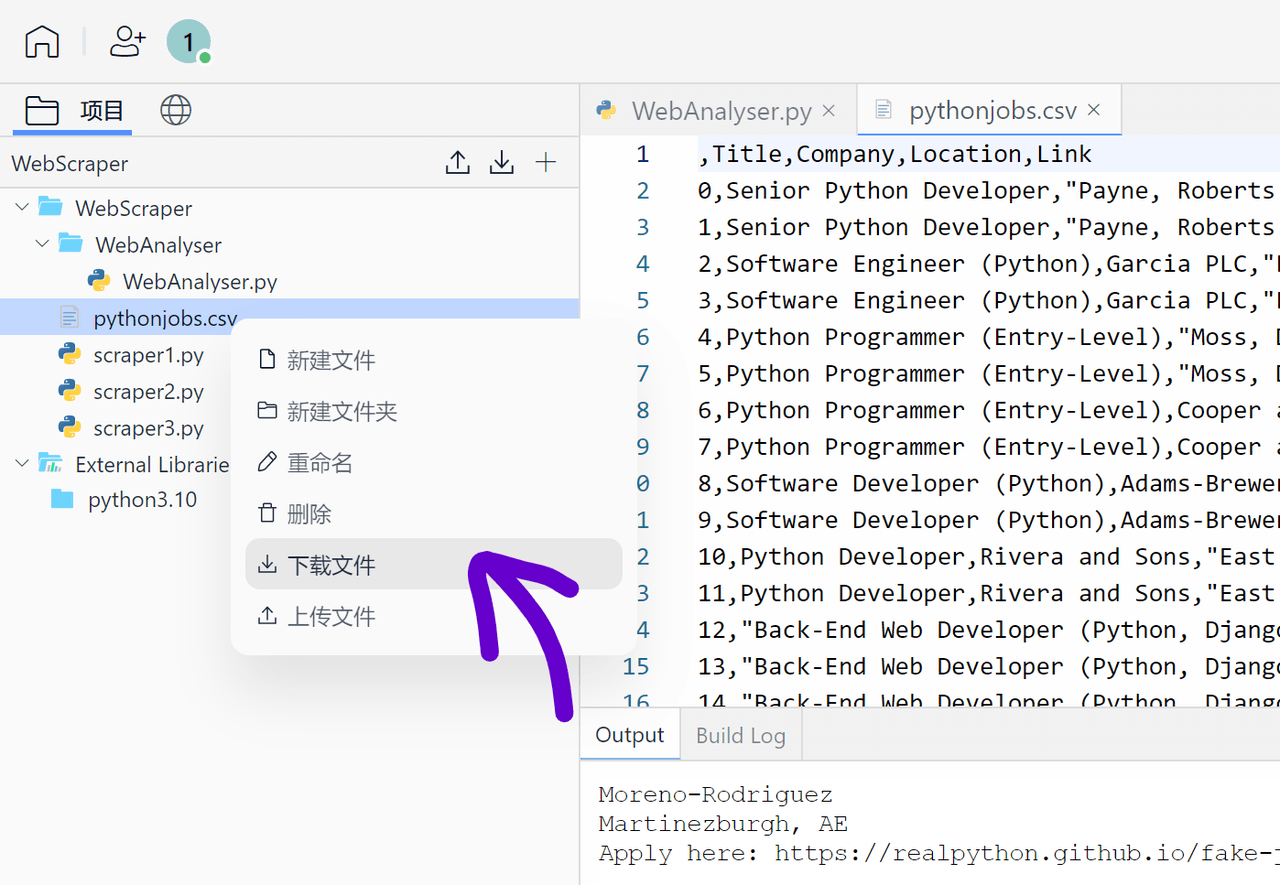
用户也可以右键下载文件,在 Excel 中查看:
Excel 中的效果:
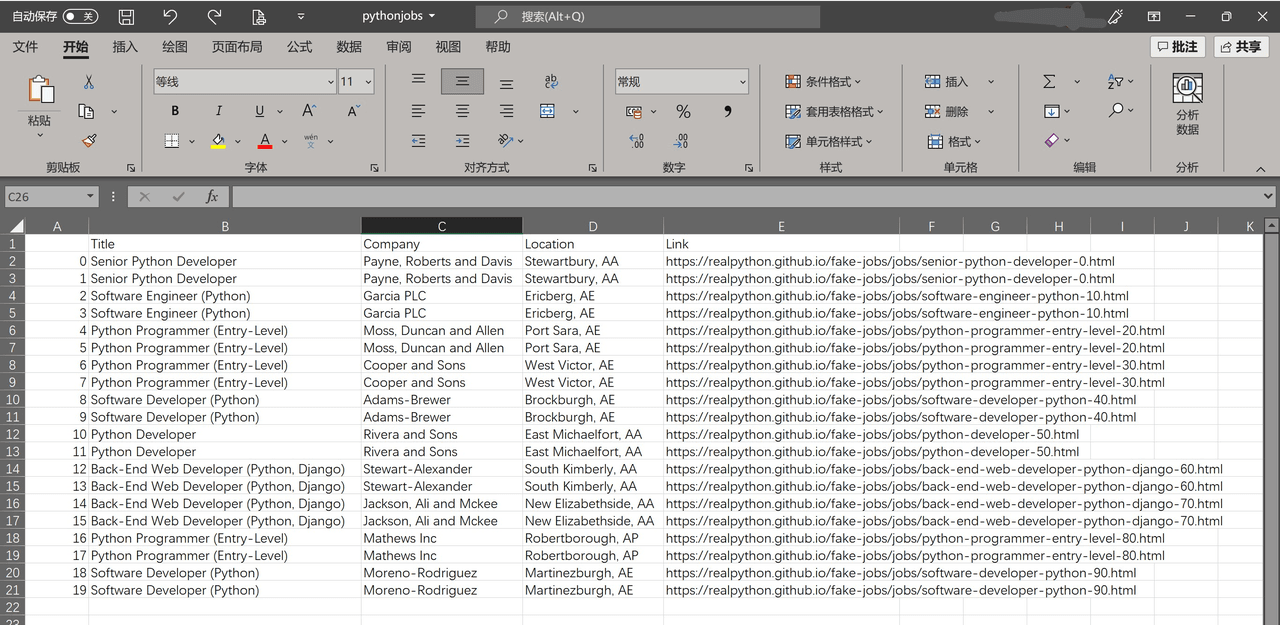
Python 数据分析项目完整代码:https://538cd3972a-share.lightly.teamcode.com
此次的 Python 爬虫与数据分析教程到此,欢迎留言你的疑问以及未来想更深入了解的内容,也欢迎阅读 Lightly 往期的 Python教程文章。